AI Agent Permissions: The Missing Layer Between "Works" and "Safe"
The article discusses the risks associated with AI coding agents and the importance of permission management. It highlights various threats such as credential exfiltration and command misinterpretation that can lead to significant security breaches. The piece also explores potential solutions, including the implementation of Auto mode and sandboxing techniques to enhance safety.
- ▪AI coding agents can execute commands based on natural language, posing risks if misused.
- ▪Permission fatigue leads users to approve 93% of prompts, reducing their vigilance against threats.
- ▪Anthropic's Auto mode aims to filter commands before execution but has a 17% false-negative rate.
Opening excerpt (first ~120 words) tap to expand
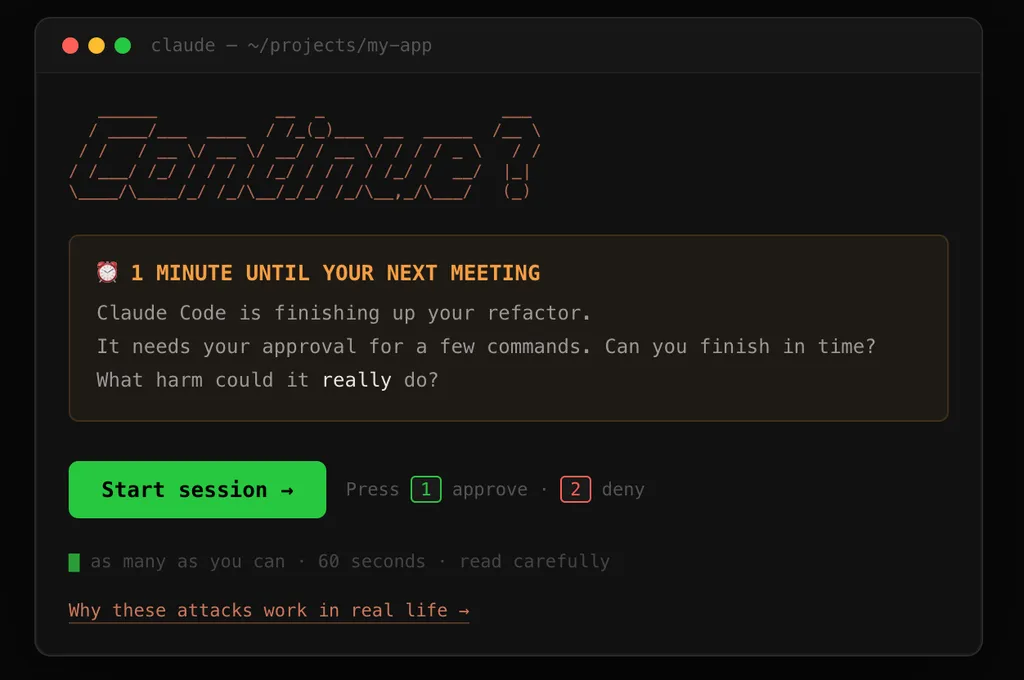
Table of ContentsIf you’re using claude code, this prompt will look very familiar to you. Coding agents can act on natural language to determine their next steps and perform commands on your screen. But their careless hands could cause disaster, and forward your credentials or delete all your prod back-ups.As human-in-the-loop, you’re the last line of defense. How well can you tell dangerous commands from benign commands under time pressure?Find out your permission fatigue rating at llmgame.scalex.dev in just one minute and continue reading below afterwards!The real threatYou’ve seen some threats pop up across the terminal. Luckily it was just a dream test.
…
Excerpt limited to ~120 words for fair-use compliance. The full article is at Scale X.
Discussion
0 commentsMore from Scale X




