I Spent May Evaluating Different Engines for OCR
The article discusses an evaluation of various OCR engines conducted by the author, testing fourteen different engines on ninety-three documents. The findings indicate that there is no single best OCR engine, with different models excelling in different areas. The author emphasizes the importance of selecting the right OCR solution based on document type and cost-effectiveness.
- ▪The author tested fourteen OCR engines on ninety-three documents of varying difficulty.
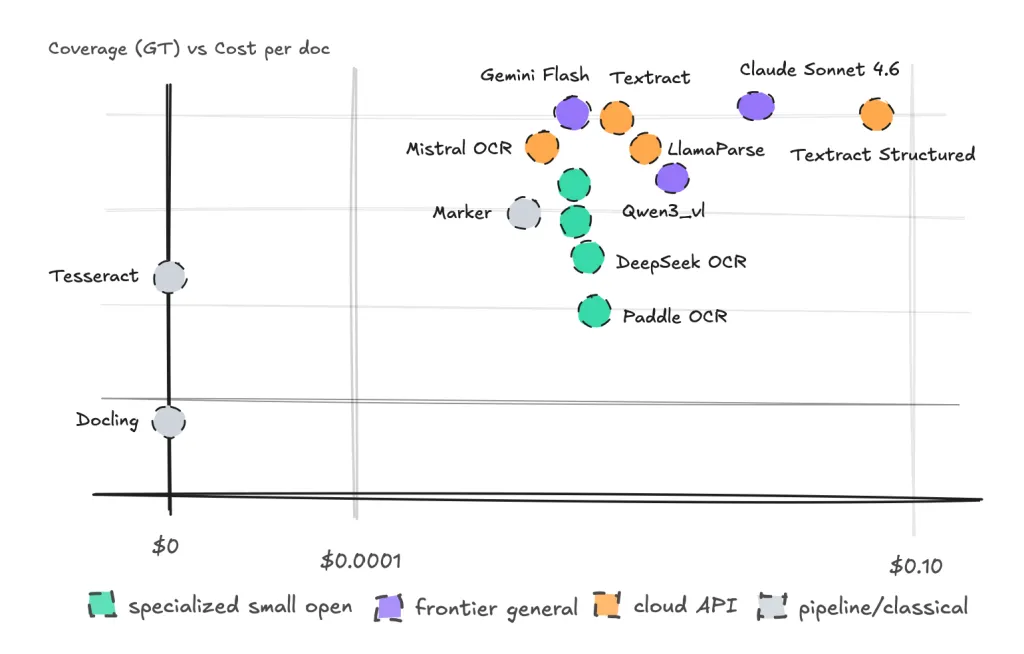
- ▪Tesseract is noted for its speed and cost-effectiveness for clean high-volume documents.
- ▪For mixed production documents, Gemini Flash was identified as the best all-rounder in the tests.
Opening excerpt (first ~120 words) tap to expand
Machine Learning I Spent May Evaluating Different Engines for OCR Testing fourteen engines on ninety-three human documents Ida Silfverskiöld Jun 3, 2026 17 min read Share Just for fun - there is an actual scatter chart further down | Images by author Not all documents were supposed to be read by a machine. Old hotel invoices, bank statements, payslips, loan applications, medical bills, customs forms, court filings, work orders. Most companies use free tools alongside paid APIs to try to convert these documents, and if you want structured output, APIs like Textract Structured run you up to around $65 per 1k pages.
…
Excerpt limited to ~120 words for fair-use compliance. The full article is at Towards Data Science.
Discussion
0 commentsMore from Towards Data Science