The Transformer: The Life of a Token
The article provides an in-depth exploration of the internals of a modern dense transformer, specifically focusing on the Rnj 1.5 model. It discusses various components such as the forward pass, normalization layers, and attention mechanisms. The post also highlights the collaborative efforts of the team behind Rnj 1.5 and its advancements over previous versions.
- ▪Rnj 1.5 extends the context window from 32k to 160k and scores 79% on RULER with a 128k context window.
- ▪The article is structured into seven parts, covering topics like the forward pass, normalization, and multi-head self-attention.
- ▪The tokenizer used in the model maps text to a sequence of tokens, which are then processed through various stages before training.
Hacker News (Newest) files mainly under programming. We currently carry 5,306 of its stories.
Story provenance
Source · retrieval · rights · ranking — open for full record
inspect →
Attribution is not the same as permission. This drawer separates discovery metadata, excerpts, WeSearch-generated summaries, reuse status, and whether the publisher receives the visit. Nothing here claims a legal grant the publisher has not made.
Record
| Original publisher | Aleksagordic |
| Canonical URL | https://www.aleksagordic.com/blog/transformer |
| Publication time | Tue, 26 May 2026 17:30:05 +0000 |
| Retrieval time | 2026-05-26T17:37:50.291Z |
| Last seen | 2026-05-26T17:37:50.291Z |
| Headline source | Publisher (no WeSearch rewrite) |
| Excerpt source | publisher body |
| Excerpt method | First ~120 words (~800 chars) of extracted publisher body, fair-use limited. |
| Summary | WeSearch · cerebras-chat (WeSearch summarizer) |
| Summary source text | contentText |
| Citation coverage | Summary is a WeSearch-generated derivative; primary citation is the original publisher URL. |
| Cluster | DAOclU9-nfrs |
| Cluster logic | Grouped by semantic title/content similarity across sources within a rolling window. Same-publisher template collisions are excluded from coverage comparison. |
| Ranking reason | Story pages are not engagement-ranked. Hub feeds use recency, with optional source-diversified chronological ordering (cap consecutive stories per source). No personalized ranking. |
| Publisher visit | Yes — open original |
| Substitutes article? | No — link-out required for full text |
Rights status (four layers)
WeSearch handling by dimension
| Indexing | May the item be indexed (stored, ranked, made findable)? | Allowed |
| Snippet | May a short excerpt of the publisher's text be shown? | Allowed |
| AI summary | May WeSearch generate its own short summary of the article? | Limited |
| Retrieval / RAG | May the content be exposed for third-party retrieval-augmented generation? | Not asserted |
| Model training | May the content be used to train AI models? | Not asserted |
| Commercial reuse | May the content be reused commercially? | Not permitted |
Basis: Derived from the published RSS/Atom feed. Contact: [email protected]. Reviewed: 2026-07-24.
Opening excerpt (first ~120 words) tap to expand
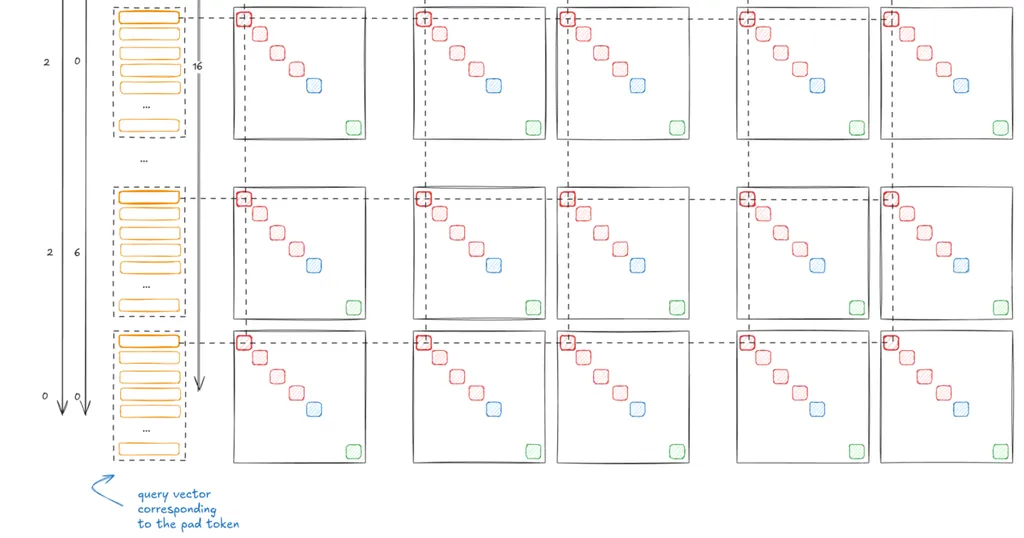
Inside the Transformer: The Life of a TokenA deep dive into a modern dense transformer: YaRN, hybrid attention, soft capping, QK normalization, FLOPs/token, cluster sizing, and moreMay 26, 2026In this post, I'll do a deep dive into the internals of a modern dense transformer [1]. I'll focus exclusively on the forward pass on a single GPU, as if we were about to perform a training step, while ignoring the backward pass and distributed systems details (in practice, large Transformers are sharded across multiple devices during both training and inference).As a running example, I'll use the exact architecture of Rnj 1.5 - a model I worked on with my team at Ashish Vaswani's AI Lab (Essential AI Labs).💡The team behind Rnj-1.5:Rnj 1.5 could not have happened without an amazing group of people…
Excerpt limited to ~120 words for fair-use compliance. The full article is at Aleksagordic.
Discussion
0 commentsMore from Aleksagordic