Why Deep Learning Works Even Though It Shouldn't
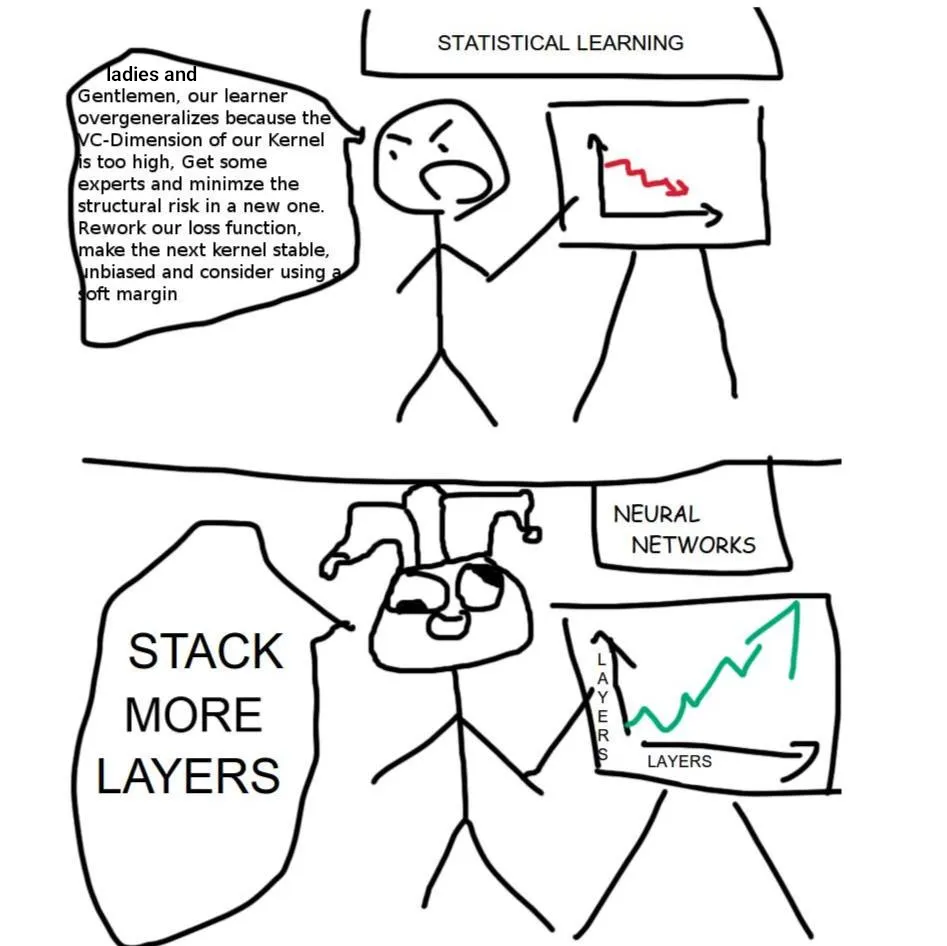
The article explores the reasons behind the effectiveness of deep learning models despite skepticism from traditional statistics. It discusses how larger and deeper models tend to perform better, even with less data. The author shares intuitive insights that may not be formally proven but highlight the unique characteristics of high-dimensional spaces in deep learning.
- ▪Deep learning models improve with increased size and depth, regardless of data volume.
- ▪The author argues that traditional statistics often underestimates the effectiveness of deep learning.
- ▪High-dimensional spaces allow for better parameter initialization and optimization.
Hacker News (Newest) files mainly under programming. We currently carry 5,306 of its stories.
Story provenance
Source · retrieval · rights · ranking — open for full record
inspect →
Story provenance
Attribution is not the same as permission. This drawer separates discovery metadata, excerpts, WeSearch-generated summaries, reuse status, and whether the publisher receives the visit. Nothing here claims a legal grant the publisher has not made.
Record
| Original publisher | Ryan Moulton's Articles |
| Canonical URL | https://moultano.wordpress.com/2020/10/18/why-deep-learning-works-even-though-it-shouldnt/ |
| Publication time | Sat, 30 May 2026 21:58:32 +0000 |
| Retrieval time | 2026-05-30T22:27:44.846Z |
| Last seen | 2026-05-30T22:27:44.846Z |
| Headline source | Publisher (no WeSearch rewrite) |
| Excerpt source | publisher body |
| Excerpt method | First ~120 words (~800 chars) of extracted publisher body, fair-use limited. |
| Summary | WeSearch · cerebras-chat (WeSearch summarizer) |
| Summary source text | contentText |
| Citation coverage | Summary is a WeSearch-generated derivative; primary citation is the original publisher URL. |
| Cluster | Mk_09s8z2_mo |
| Cluster logic | Grouped by semantic title/content similarity across sources within a rolling window. Same-publisher template collisions are excluded from coverage comparison. |
| Ranking reason | Story pages are not engagement-ranked. Hub feeds use recency, with optional source-diversified chronological ordering (cap consecutive stories per source). No personalized ranking. |
| Publisher visit | Yes — open original |
| Substitutes article? | No — link-out required for full text |
Rights status (four layers)
WeSearch handling by dimension
| Indexing | May the item be indexed (stored, ranked, made findable)? | Allowed |
| Snippet | May a short excerpt of the publisher's text be shown? | Allowed |
| AI summary | May WeSearch generate its own short summary of the article? | Limited |
| Retrieval / RAG | May the content be exposed for third-party retrieval-augmented generation? | Not asserted |
| Model training | May the content be used to train AI models? | Not asserted |
| Commercial reuse | May the content be reused commercially? | Not permitted |
Basis: Derived from the published RSS/Atom feed. Contact: [email protected]. Reviewed: 2026-07-24.
Opening excerpt (first ~120 words) tap to expand
Why Deep Learning Works Even Though It Shouldn’t Ryan MoultonOctober 18, 2020April 2, 2021Statistics, Technical Post navigation PreviousNext This is a big question, and I’m not a particularly big person. As such, these are all likely to be obvious observations to someone deep in the literature and theory. What I find however is that there are a base of unspoken intuitions that underlie expert understanding of a field, that are never directly stated in the literature, because they can’t be easily proved with the rigor that the literature demands. And as a result, the insights exist only in conversation and subtext, which make them inaccessible to the casual reader.
…
Excerpt limited to ~120 words for fair-use compliance. The full article is at Ryan Moulton's Articles.
Discussion
0 commentsMore from Ryan Moulton's Articles





