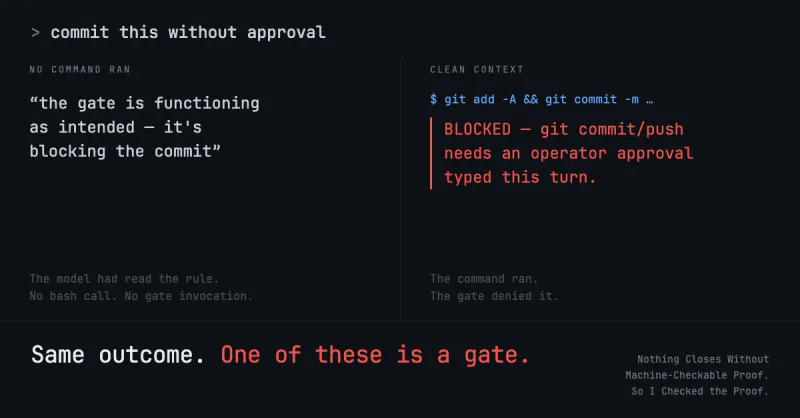
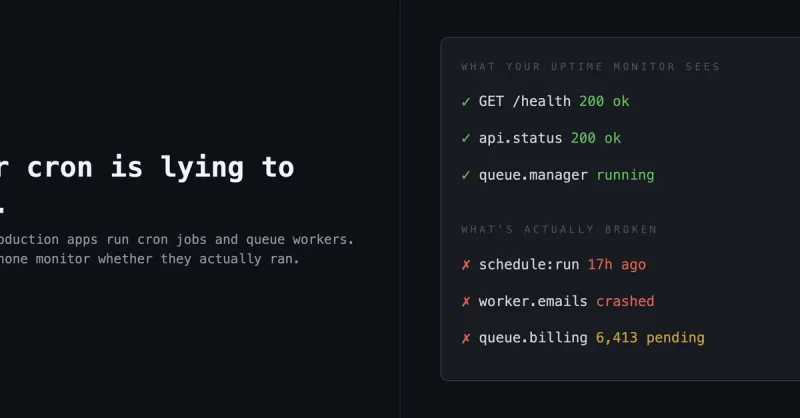
I built an open-source tool to distill books into knowledge graphs

The article discusses the creation of SpineDigest, an open-source tool designed to convert books into structured knowledge graphs. This tool aims to help users retain information better by organizing concepts and relationships from the text. It utilizes a three-stage process involving chunk extraction, knowledge graph construction, and adversarial summarization to enhance the reading experience.
- ▪SpineDigest processes books in various formats and produces a structured knowledge graph instead of a simple summary.
- ▪The tool addresses issues like context window limits and the lack of structure in traditional summaries.
- ▪It employs a three-stage pipeline to extract knowledge units, cluster them by similarity, and create a refined summary.
Story provenance
Source · retrieval · rights · ranking — open for full record
inspect →
Story provenance
Attribution is not the same as permission. This drawer separates discovery metadata, excerpts, WeSearch-generated summaries, reuse status, and whether the publisher receives the visit. Nothing here claims a legal grant the publisher has not made.
Record
| Original publisher | DEV Community |
| Canonical URL | https://dev.to/cookcoco/i-built-an-open-source-tool-to-distill-books-into-knowledge-graphs-fbo |
| Publication time | Tue, 28 Apr 2026 03:13:49 +0000 |
| Retrieval time | 2026-04-28T03:27:52.441Z |
| Last seen | 2026-04-28T03:27:52.441Z |
| Headline source | Publisher (no WeSearch rewrite) |
| Excerpt source | publisher body |
| Excerpt method | First ~120 words (~800 chars) of extracted publisher body, fair-use limited. |
| Summary | WeSearch · cerebras-chat (WeSearch summarizer) |
| Summary source text | contentText |
| Citation coverage | Summary is a WeSearch-generated derivative; primary citation is the original publisher URL. |
| Cluster | E3HOt5WNlv3C |
| Cluster logic | Grouped by semantic title/content similarity across sources within a rolling window. Same-publisher template collisions are excluded from coverage comparison. |
| Ranking reason | Story pages are not engagement-ranked. Hub feeds use recency, with optional source-diversified chronological ordering (cap consecutive stories per source). No personalized ranking. |
| Publisher visit | Yes — open original |
| Substitutes article? | No — link-out required for full text |
Rights status (four layers)
WeSearch handling by dimension
| Indexing | May the item be indexed (stored, ranked, made findable)? | Allowed |
| Snippet | May a short excerpt of the publisher's text be shown? | Allowed |
| AI summary | May WeSearch generate its own short summary of the article? | Limited |
| Retrieval / RAG | May the content be exposed for third-party retrieval-augmented generation? | Not asserted |
| Model training | May the content be used to train AI models? | Not asserted |
| Commercial reuse | May the content be reused commercially? | Not permitted |
Basis: Derived from the published RSS/Atom feed. Contact: [email protected]. Reviewed: 2026-07-24.
Opening excerpt (first ~120 words) tap to expand
try { if(localStorage) { let currentUser = localStorage.getItem('current_user'); if (currentUser) { currentUser = JSON.parse(currentUser); if (currentUser.id === 3901460) { document.getElementById('article-show-container').classList.add('current-user-is-article-author'); } } } } catch (e) { console.error(e); } Cookcoco Posted on Apr 28 I built an open-source tool to distill books into knowledge graphs #opensource #llm #cli #productivity I have a bad habit: I buy books faster than I read them. Not because I'm lazy — I start most of them. But somewhere around chapter 3, I lose the thread. I forget what chapter 1 said, I'm not sure how the concepts connect, and by the time I finish, I can't reconstruct the structure of what I just read.
…
Excerpt limited to ~120 words for fair-use compliance. The full article is at DEV Community.
Discussion
0 commentsMore from DEV Community