The Next Frontier of AI in Production Is Chaos Engineering

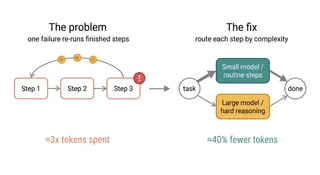
Chaos engineering in AI production systems currently emphasizes safety over intent, focusing on whether experiments stay within error budgets rather than whether they yield meaningful insights. The article argues that while tools exist to ensure safe failure injection, there is a lack of systems that determine which experiments would be most informative. A shift toward intent-based chaos engineering is needed to align experiments with learning goals and improve understanding of system failure behavior.
- ▪Current chaos engineering tools prioritize safety by ensuring experiments stay within SLO error budgets but do not assess whether the experiment teaches something valuable.
- ▪The core issue is that static scripts used in chaos engineering become outdated as systems evolve, leading to tests that reflect obsolete system states.
- ▪Intent-based chaos engineering aims to design experiments that update the team's understanding of failure propagation, rather than just verifying recovery.
- ▪The article references a patented architecture (US12242370B2) for intent-based chaos engineering and draws on insights from engineers at companies like Intuit and GPTZero.
- ▪Safety determines how much to break; intent determines what breaking it will teach—these require different tooling, but only the former is well-developed.
Towards Data Science files mainly under ai. We currently carry 100 of its stories.
Story provenance
Source · retrieval · rights · ranking — open for full record
inspect →
Story provenance
Attribution is not the same as permission. This drawer separates discovery metadata, excerpts, WeSearch-generated summaries, reuse status, and whether the publisher receives the visit. Nothing here claims a legal grant the publisher has not made.
Record
| Original publisher | Towards Data Science |
| Canonical URL | https://towardsdatascience.com/the-next-frontier-of-ai-in-production-is-chaos-engineering/ |
| Publication time | Tue, 28 Apr 2026 13:30:00 +0000 |
| Retrieval time | 2026-04-28T13:34:31.939Z |
| Last seen | 2026-04-28T13:34:31.939Z |
| Headline source | Publisher (no WeSearch rewrite) |
| Excerpt source | publisher body |
| Excerpt method | First ~120 words (~800 chars) of extracted publisher body, fair-use limited. |
| Summary | WeSearch · cerebras-chat (WeSearch summarizer) |
| Summary source text | contentText |
| Citation coverage | Summary is a WeSearch-generated derivative; primary citation is the original publisher URL. |
| Cluster | _yn7e3Pqjwj0 |
| Cluster logic | Grouped by semantic title/content similarity across sources within a rolling window. Same-publisher template collisions are excluded from coverage comparison. |
| Ranking reason | Story pages are not engagement-ranked. Hub feeds use recency, with optional source-diversified chronological ordering (cap consecutive stories per source). No personalized ranking. |
| Publisher visit | Yes — open original |
| Substitutes article? | No — link-out required for full text |
Rights status (four layers)
WeSearch handling by dimension
| Indexing | May the item be indexed (stored, ranked, made findable)? | Allowed |
| Snippet | May a short excerpt of the publisher's text be shown? | Allowed |
| AI summary | May WeSearch generate its own short summary of the article? | Limited |
| Retrieval / RAG | May the content be exposed for third-party retrieval-augmented generation? | Not asserted |
| Model training | May the content be used to train AI models? | Not asserted |
| Commercial reuse | May the content be reused commercially? | Not permitted |
Basis: Derived from the published RSS/Atom feed. Contact: [email protected]. Reviewed: 2026-07-24.
Opening excerpt (first ~120 words) tap to expand
Artificial Intelligence The Next Frontier of AI in Production Is Chaos Engineering Blast-radius control tells you how much to break. Intent tells you what breaking it will teach. Only one of these has mature tooling. Sayali Patil Apr 28, 2026 18 min read Share Image by Growtika, via Unsplash Here is a question that no chaos engineering tool in production today can answer: Did your last experiment test the right thing? Not ‘Did it stay within budget?’ That is what SLO error-budget gating handles. Not ‘Did the system survive?’ That is what abort conditions measure. The question is whether the experiment was designed to validate a specific belief about your system’s behavior, and whether its outcome changed what your team knows about failure propagation through your stack.
…
Excerpt limited to ~120 words for fair-use compliance. The full article is at Towards Data Science.
Discussion
0 commentsMore from Towards Data Science