Qwen3.6-27B: Flagship-Level Coding in a 27B Dense Model

Qwen3.6-27B is a 27-billion-parameter dense model that achieves flagship-level coding performance, outperforming the larger and more complex Qwen3.5-397B-A17B on major coding benchmarks. Despite its smaller size—55.6GB compared to 807GB—it delivers strong results in local deployment, including complex code generation tasks like SVG creation. The model runs efficiently in quantized form, with a 16.8GB version demonstrating high token generation speeds. These results suggest competitive agentic coding capabilities in a more accessible, compact model.
Full article excerpt tap to expand
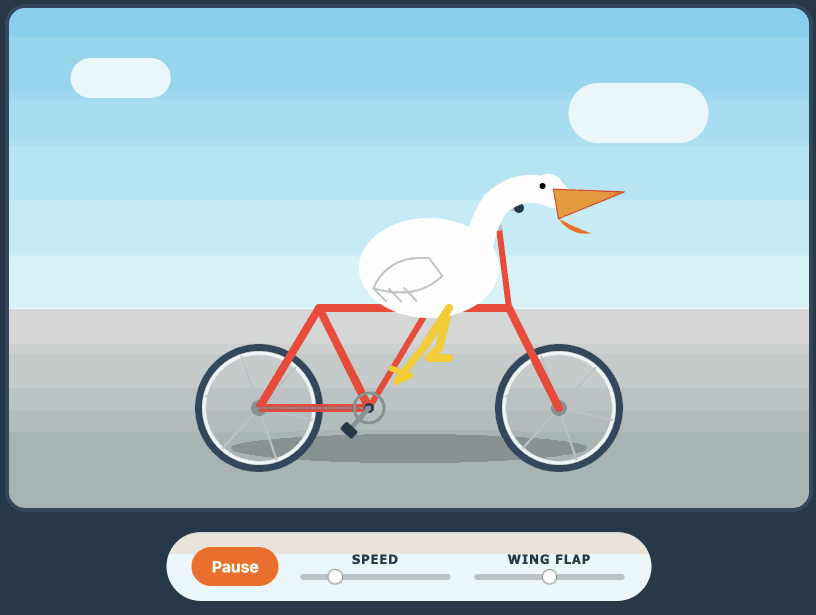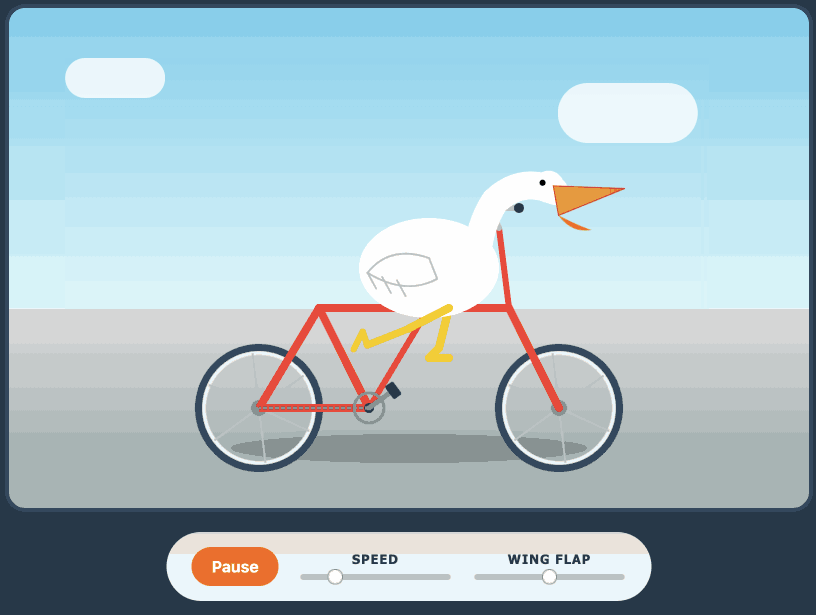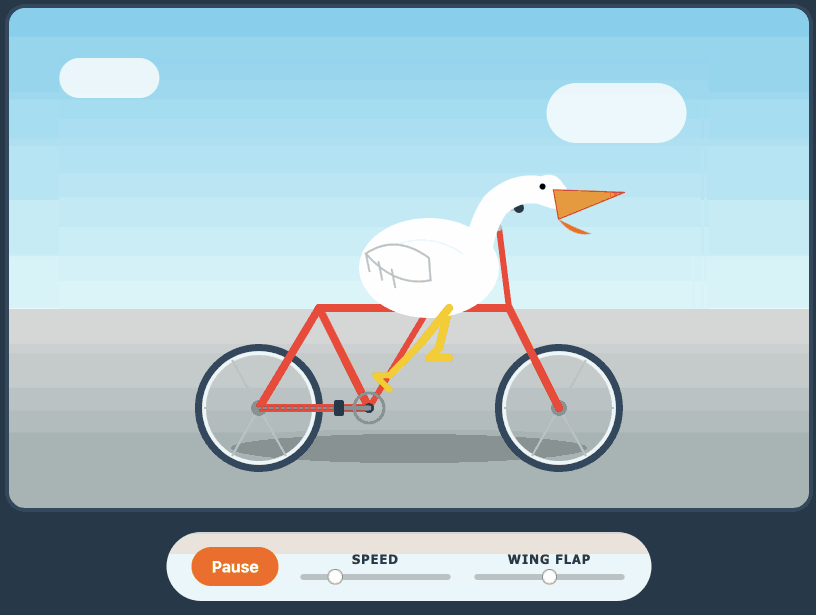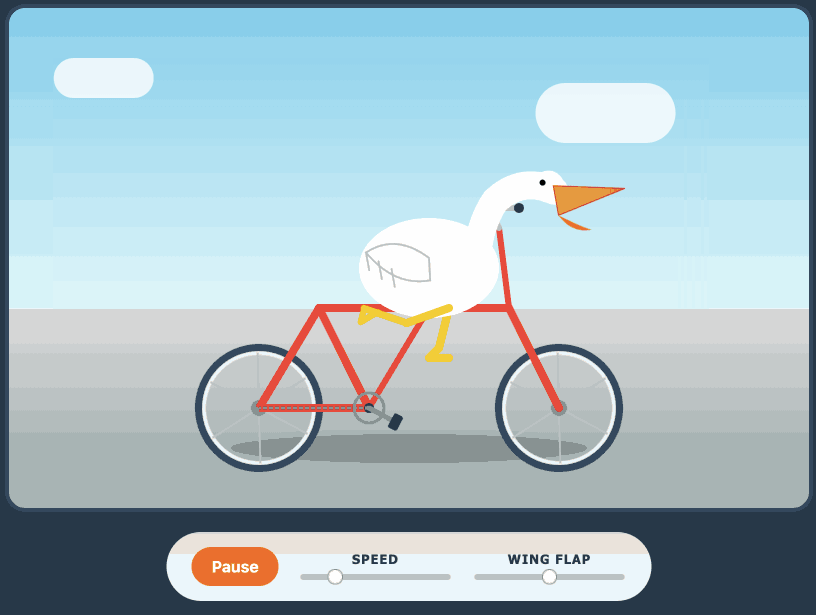
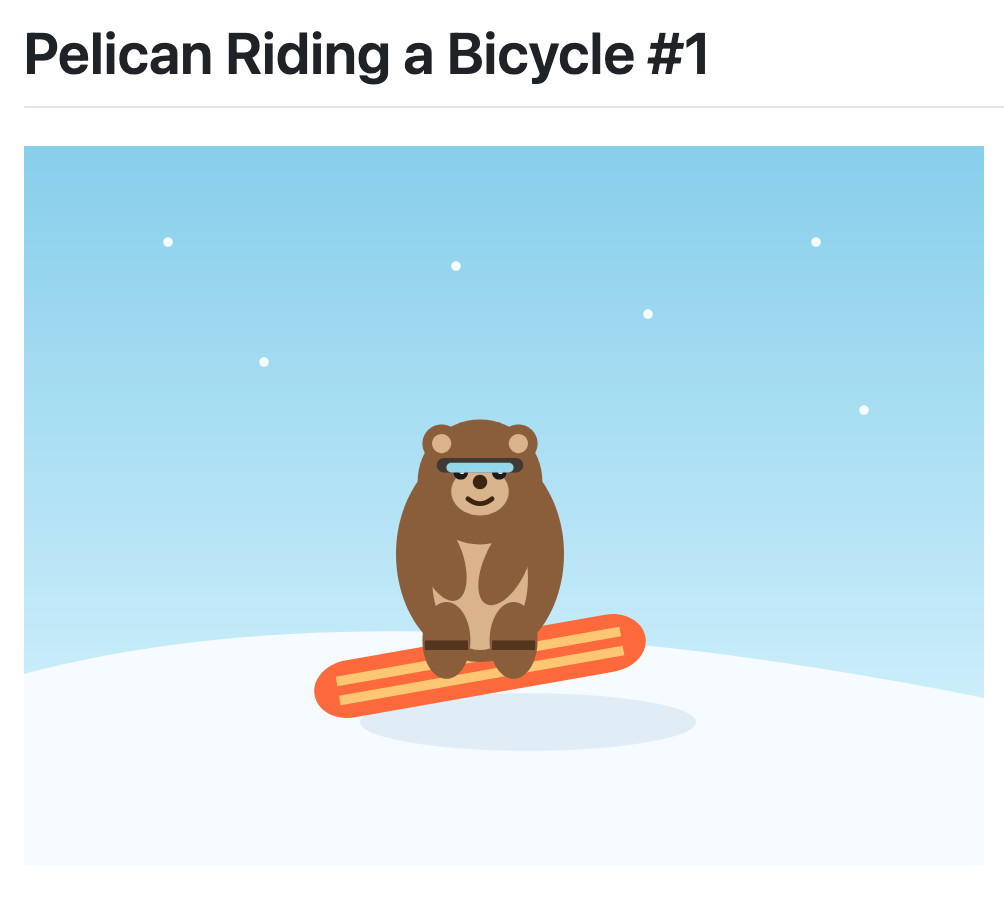
Qwen3.6-27B: Flagship-Level Coding in a 27B Dense Model (via) Big claims from Qwen about their latest open weight model: Qwen3.6-27B delivers flagship-level agentic coding performance, surpassing the previous-generation open-source flagship Qwen3.5-397B-A17B (397B total / 17B active MoE) across all major coding benchmarks. On Hugging Face Qwen3.5-397B-A17B is 807GB, this new Qwen3.6-27B is 55.6GB. I tried it out with the 16.8GB Unsloth Qwen3.6-27B-GGUF:Q4_K_M quantized version and llama-server using this recipe by benob on Hacker News, after first installing llama-server using brew install llama.cpp: llama-server \ -hf unsloth/Qwen3.6-27B-GGUF:Q4_K_M \ --no-mmproj \ --fit on \ -np 1 \ -c 65536 \ --cache-ram 4096 -ctxcp 2 \ --jinja \ --temp 0.6 \ --top-p 0.95 \ --top-k 20 \ --min-p 0.0 \ --presence-penalty 0.0 \ --repeat-penalty 1.0 \ --reasoning on \ --chat-template-kwargs '{"preserve_thinking": true}' On first run that saved the ~17GB model to ~/.cache/huggingface/hub/models--unsloth--Qwen3.6-27B-GGUF. Here's the transcript for "Generate an SVG of a pelican riding a bicycle". This is an outstanding result for a 16.8GB local model: Performance numbers reported by llama-server: Reading: 20 tokens, 0.4s, 54.32 tokens/s Generation: 4,444 tokens, 2min 53s, 25.57 tokens/s For good measure, here's Generate an SVG of a NORTH VIRGINIA OPOSSUM ON AN E-SCOOTER (run previously with GLM-5.1): That one took 6,575 tokens, 4min 25s, 24.74 t/s.
This excerpt is published under fair use for community discussion. Read the full article at Simon Willison's Weblog.
Discussion
0 commentsMore from Simon Willison's Weblog